Compression des données de graphes : du traitement du signal à l'apprentissage automatique
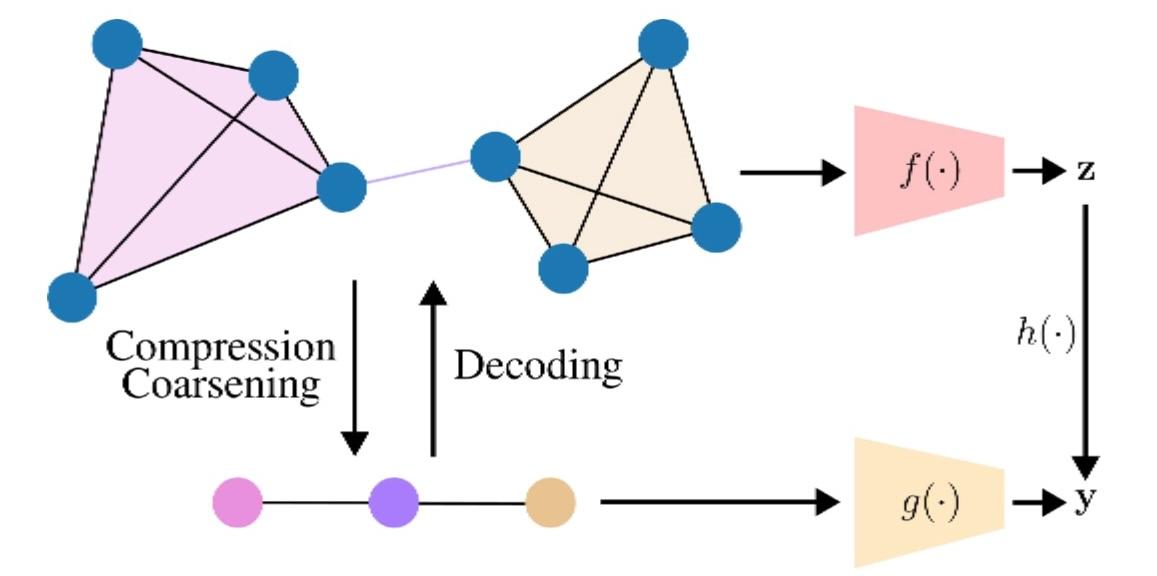
Description
Le traitement des signaux de graphes (GSP) [1-3] et l'apprentissage automatique des graphes (GML) [4-6] sont des domaines de recherche qui visent à généraliser les concepts classiques du traitement des signaux et de l'apprentissage automatique aux données définies sur des graphes. Dans le GSP, les opérations classiques telles que le filtrage, l'échantillonnage et la reconstruction sont étendues aux signaux de graphes, c'est-à-dire aux fonctions définies sur les sommets d'un graphe [7,8]. Dans le GML, les architectures de réseaux neuronaux sont adaptées aux données structurées en graphes, ce qui conduit à des modèles tels que les réseaux neuronaux à base de graphes (GNN) [9] et les réseaux neuronaux à passage de messages (MPNN) [10]. Le GSP et le GML sont essentiels car les données structurées en graphes apparaissent dans de nombreuses applications, notamment les réseaux sociaux [3], le web [11], les systèmes de recommandation [12], les réseaux biologiques [13] et les graphes de connaissances [14], entre autres. Un défi commun à tous ces domaines est l'échelle massive des graphes sous-jacents, qui contiennent souvent des millions, voire des milliards de nœuds et d'arêtes [15]. Il devient donc essentiel de compresser les signaux qui y sont définis, ce qui permet également un apprentissage et un traitement efficaces des représentations compressées.
Dans la littérature sur le GSP, de nombreux travaux ont abordé les problèmes d'échantillonnage et de reconstruction des signaux de graphes de manière systématique [7,16-18]. Ces travaux fournissent des garanties théoriques pour la reconstruction des signaux de graphes à partir d'échantillons basés sur les propriétés spectrales du graphe, guidant la conception d'ensembles d'échantillonnage optimaux ou quasi optimaux [8,19,20]. Cependant, ces méthodes supposent que le graphe d'origine n'est pas modifié et ne prennent en compte que le problème de l'échantillonnage des signaux de graphes. En parallèle, la communauté GML a développé des méthodes de grossissement de graphes fondées sur des principes [21] et, plus récemment, des techniques de grossissement de graphes avec des garanties de transmission de messages [22,23]. Cependant, les opérateurs de réduction/élévation et de propagation associés sont difficiles à optimiser dans la pratique, ce qui limite leur évolutivité.
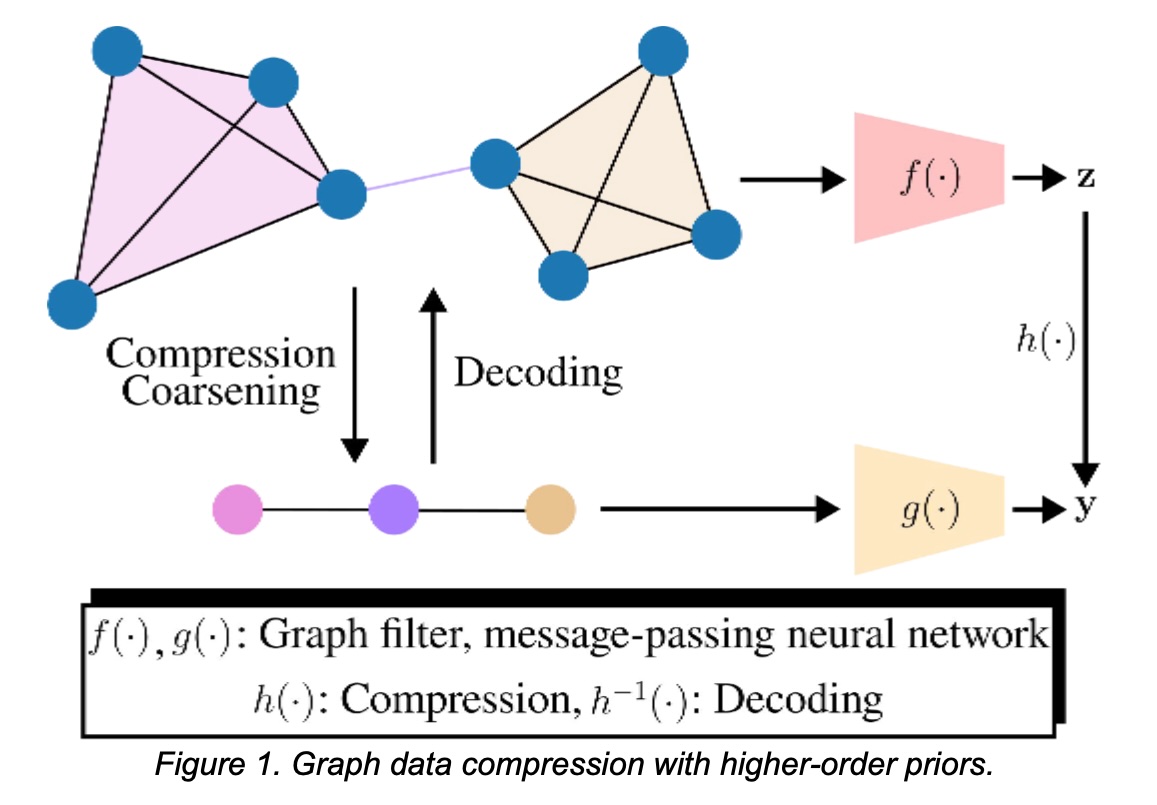
La mise en place d'un cadre fondé sur des principes pour compresser conjointement les signaux de graphes et la topologie avec (i) des garanties de décodage et (ii) des garanties au niveau des tâches sur la topologie compressée reste un défi à relever. Nous abordons cette question en supposant l'accès à des structures d'ordre supérieur (par exemple, des cliques/motifs) qui induisent un opérateur d'agrégation et un graphe compact, comme le montre la figure 1. Cette priorité nous permettra (i) de compresser les signaux et de les décoder avec certaines garanties, et (ii) d'exécuter des GNN directement sur la représentation compressée tout en préservant les performances en aval. Contrairement aux agrégations locales successives [18], qui forment des mesures en appliquant de manière répétée une fonction de décalage de graphe tout en conservant la topologie, nous supposons une priorité d'ordre supérieur, comme les cliques, qui induit l'opérateur de compression et une topologie compressée sur laquelle l'apprentissage se poursuit. De même, contrairement à la méthode de grossissement de graphes avec garanties de passage de messages qui construit des opérateurs de réduction/élévation [22,23], notre a priori d'ordre supérieur fournit la carte d'agrégation, simplifiant la conception des opérateurs tout en permettant des garanties pour la propagation GNN/MPNN. Une question clé que nous étudions est la suivante : quand ces a priori d'ordre supérieur sont-ils informatifs et utiles dans la pratique ? Nous ciblons les régimes où les cliques/motifs sont courants (par exemple, les sous-structures de type communautaire), afin que l'agrégation capture les variations douces dans la clique/le motif et préserve les performances de la tâche. Ce problème a de nombreuses applications, allant de la compression et du stockage de données de graphes au traitement efficace d'ensembles de données relationnelles dans des domaines tels que les réseaux sociaux, le web, les systèmes de recommandation et les systèmes biologiques.
Bibliographie
Bibliographie
[1] D. I. Shuman et al., “The emerging field of signal processing on graphs: Extending high- dimensional data analysis to networks and other irregular domains,” IEEE Signal Processing Magazine, vol. 30, no. 3, pp. 83–98, 2013.
[2] A. Ortega et al., “Graph signal processing: Overview, challenges, and applications,” Proceedings of the IEEE, vol. 106, no. 5, pp. 808–828, 2018.
[3] A. Ortega, Introduction to Graph Signal Processing. Cambridge University Press, 2022.
[4] M. M. Bronstein et al., “Geometric deep learning: going beyond Euclidean data,” IEEE Signal Processing Magazine, vol. 34, no. 4, pp. 18–42, 2017.
[5] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, “A comprehensive survey on graph neural networks,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 1, pp. 4–24, 2021.
[6] C. Morris, F. Frasca, N. Dym, H. Maron, I. I. Ceylan, R. Levie, D. Lim, M. M. Bronstein, M. Grohe, and S. Jegelka, “Position: Future directions in the theory of graph machine learning,” in Forty-first International Conference on Machine Learning, 2024.
[7] S. Chen et al., “Discrete signal processing on graphs: Sampling theory,” IEEE Transactions on Signal Processing, vol. 63, no. 24, pp. 6510–6523, 2015.
[8] A. Anis, A. Gadde, and A. Ortega, “Efficient sampling set selection for bandlimited graph signals using graph spectral proxies,” IEEE Transactions on Signal Processing, vol. 64, no. 14, pp. 3775–3789, 2016.
[9] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in International Conference on Learning Representations (ICLR), 2017.
[10] J. Gilmer et al., “Neural message passing for quantum chemistry,” in International Conference on Machine Learning (ICML), vol. 70, 2017, pp. 1263–1272.
[11] G. Wang, J. Yu, M. Nguyen, Y. Zhang, S. Yongchareon, and Y. Han, “Motif-based graph attentional neural network for web service recommendation,” Knowledge-Based Systems, vol. 269, p. 110512, 2023.
[12] X. Li, L. Sun, M. Ling, and Y. Peng, “A survey of graph neural network based recommendation in social networks,” Neurocomputing, vol. 549, p. 126441, 2023.
[13] R. Li, X. Yuan, M. Radfar, P. Marendy, W. Ni, T. J. O’Brien, and P. M. Casillas-Espinosa, “Graph signal processing, graph neural network and graph learning on biological data: a systematic review,” IEEE Reviews in Biomedical Engineering, vol. 16, pp. 109–135, 2021.
[14] Z. Ye, Y. J. Kumar, G. O. Sing, F. Song, and J. Wang, “A comprehensive survey of graph neural networks for knowledge graphs,” IEEE Access, vol. 10, pp. 75 729–75 741, 2022.
[15] J. Leskovec and A. Krevl, “SNAP Datasets: Stanford large network dataset collection,” http://snap.stanford.edu/data, June 2014.
[16] I. Pesenson, “Sampling in paley–wiener spaces on combinatorial graphs,” Transactions of the American Mathematical Society, vol. 360, no. 10, pp. 5603–5627, 2008.
[17] M. Tsitsvero, S. Barbarossa, and P. D. Lorenzo, “Signals on graphs: Uncertainty principle and sampling,” IEEE Transactions on Signal Processing, vol. 64, no. 18, pp. 4845–4860, 2016.
[18] A. G. Marques, S. Segarra, G. Leus, and A. Ribeiro, “Sampling of graph signals with successive local aggregations,” IEEE Transactions on Signal Processing, vol. 64, no. 7, pp. 1832–1843, 2016.
[19] G. Puy, N. Tremblay, R. Gribonval, and P. Vandergheynst, “Random sampling of bandlimited signals on graphs,” Applied and Computational Harmonic Analysis, vol. 44, no. 2, pp. 446–475, 2018.
[20] Y. Tanaka, Y. C. Eldar, A. Ortega, and G. Cheung, “Sampling signals on graphs: From theory to applications,” IEEE Signal Processing Magazine, vol. 37, no. 6, pp. 14–30, 2020.
[21] A. Loukas, “Graph reduction with spectral and cut guarantees,” Journal of Machine Learning Research, vol. 20, no. 116, pp. 1–42, 2019.
[22] A. Joly and N. Keriven, “Graph coarsening with message-passing guarantees,” Advances in Neural Information Processing Systems, vol. 37, pp. 114 902–114 927, 2024.
[23] A. Joly, N. Keriven, and A. Roumy, “Taxonomy of reduction matrices for graph coarsening,” in NeurIPS, 2025.

